Visualize Student Performance with ggplot2: Part I
How are you compared with your peers?
 Image credit: Forbidden City
Image credit: Forbidden City
Introduction
The first Pop Quiz was held around 7pm on Sep 24, 2021. The Quiz consists of ten Multiple Choices Questions which is designed to test your fundamental understanding of the basics of R programming. The Quiz has been automatically graded by the computer and your marks have been published on eLearn. I have some comments on students who got 50% or lower. Please check my comments on eLearn.
This document is to provide you a review of the performance.
Summary Statistics
Here is the original file I downloaded from eLearn. It contains 42 rows and 8 columns, which can be shown by the dim() function as follows^[dim() shows the dimensions of the data frame by row and column.]. It indicates that there are 42 students who have attempted the Quiz.
df <- read.csv("popquiz1.csv")
dim(df)
## [1] 42 8
So what are the eight columns prepared by eLearn? We can use the str() function^[str() shows the structure of the data frame]. Note that the function by default will show the first 4 values of each column. As some are confidential information, I have set the vec.len argument to 0 which will not display any values.
str(df, vec.len = 0)
## 'data.frame': 42 obs. of 8 variables:
## $ Org.Defined.ID : int NULL ...
## $ Username : chr ...
## $ FirstName : chr ...
## $ Score : int NULL ...
## $ Out.Of : int NULL ...
## $ X. : chr ...
## $ Class.Average : chr ...
## $ Class.Standard.Deviation: chr ...
Alternatively, you may mask some columns by removing them from the dataframe. Note that you have to use number index of columns if you want to use - to remove columns. You cannot use the name of columns. You may try str(df[, -c("Score")]) and it will not work.
str(df[, -c(1:4, 6)])
## 'data.frame': 42 obs. of 3 variables:
## $ Out.Of : int 10 10 10 10 10 10 10 10 10 10 ...
## $ Class.Average : chr "65.24%" "65.24%" "65.24%" "65.24%" ...
## $ Class.Standard.Deviation: chr "17.70%" "17.70%" "17.70%" "17.70%" ...
And here is the summary statistics of your Scores using the summary() function^[summary() provides summary statistics on the columns of the data frame].
summary(df$Score)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.000 5.250 7.000 6.524 8.000 10.000
As shown above, your marks range from 3 to 10 with a median value of 7 and a mean value of 6.524, indicating that half of you got 7 marks and above and the distribution is slightly left skewed^[Besides the above three functions, you may also try colnames(), head(), tail(), and View() to explore your data frame.].
The distribution can also be shown using the following plot.
library(tidyverse)
df %>% ggplot(aes(x = factor(Score), fill = factor(Score))) +
geom_bar() +
geom_text(aes(label = ..count..), stat = "count", vjust = -0.5) +
geom_text(aes(label = scales::percent(x= ..prop..), group = 1),
stat = "count", vjust = 1) +
theme(legend.position = "none") +
ggtitle("Pop Quiz 1 Count of Raw Marks") +
xlab("Raw Scores of Pop Quiz 1") +
ylab("Counts of Raw Scores")
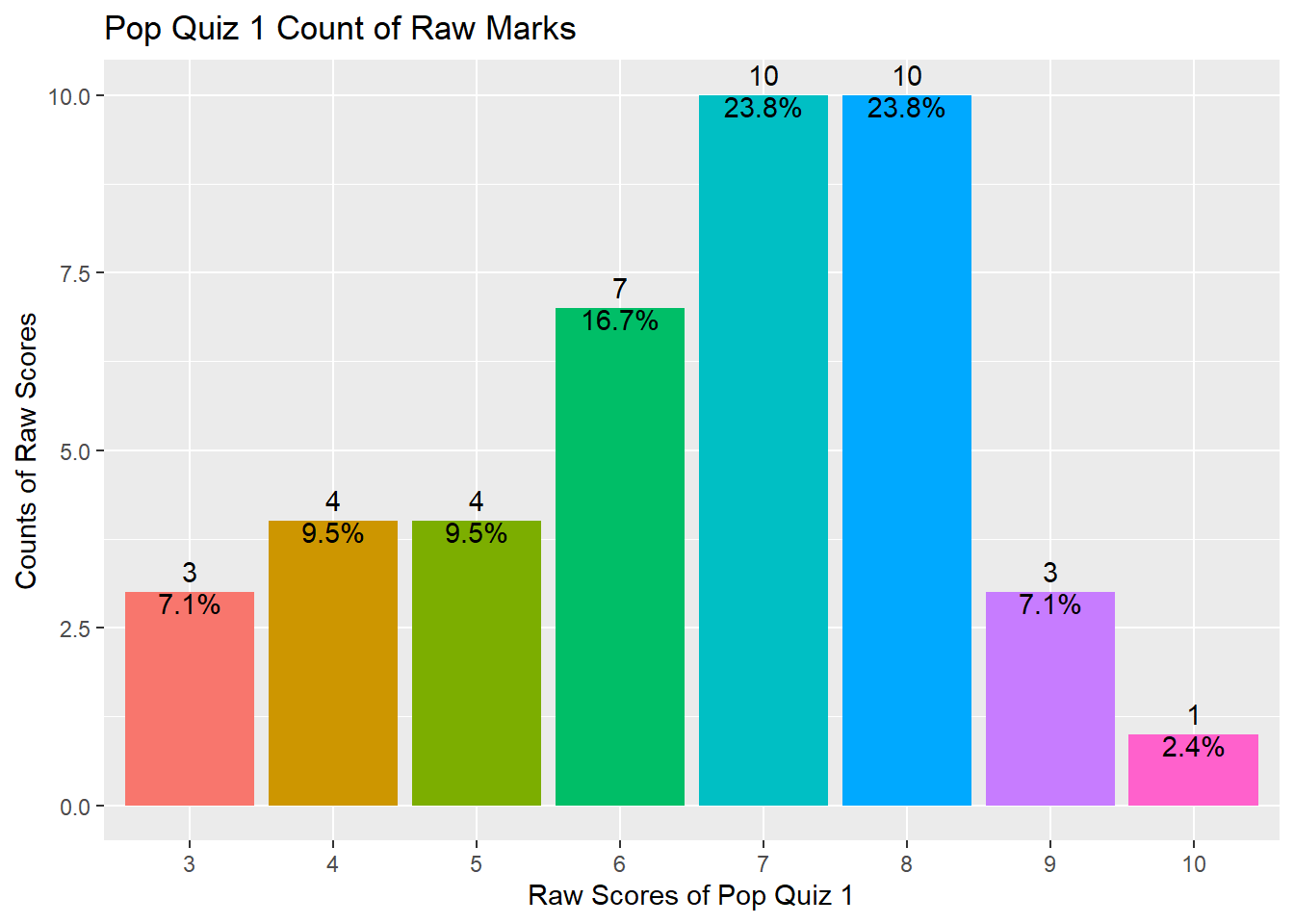
As we mentioned in class, if you don’t input the y = argument in the aes() function under ggplot(), it will automatically plot the x by counts (ie, number of observations for each value of x). This is called the frequency plot.
The above plot also shows you how to fill up color for bars, how to show number of counts as bar label, how to show percentage of counts as bar label, and how to remove all legends. You may refer to package:ggplot2 manual for more options. Of course the best teacher is always google.
The following plot presents another way to show your scores. It is the cumulative percentile of your scores. For example, if your score is 10, you are the top 100 percentile in the class. If you score is 6, you are below the top 50% percentile. I am using another package:ggthemes which includes some pre-defined themes. The theme I am using is the Economist magazine theme. Feel free to try.
library(ggthemes)
df %>% ggplot(aes(x = Score)) +
stat_ecdf() +
labs(title = "Cumulative Density of Pop Quiz 1 Scores",
y = "Percentile", x = "Pop Quiz 1 Raw Marks") +
scale_color_manual(values = c("Green")) +
theme_economist()
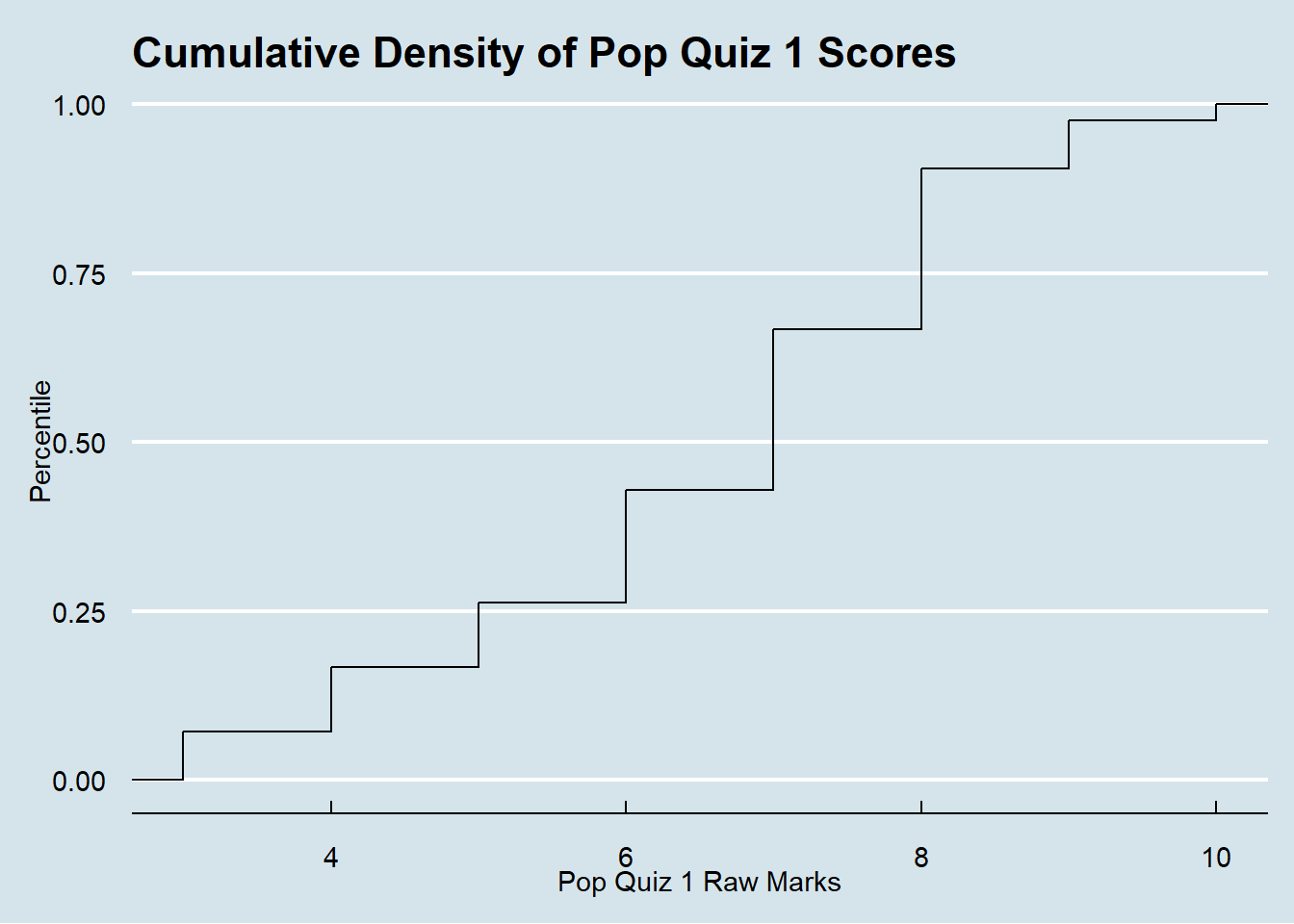
So, do you have a better understanding of your performance compared with your peers?
Hypothesis Testing
One interesting hypothesis I’d like to explore is whether the 2020 intake students perform better or worse than the 2021 intake students. Why is this interesting? Because I have different arguments which can give us different predictions^[This is the essence of an interesting research question, ie, there should be tension between different views].
The 2020 intake students may perform better because:
- they are more mature as they are on average older;
- they are more adapted to the SMU teaching style after study
~torture~in the 12 intensive MPA courses; - they are more adapted to the online learning experience.
On the other hand, the 2020 intake students may perform worse because:
- they have almost finished the program and decided to tang ping;
- they are exhausted after 12 intensive courses and have no energy left;
- some are working or doing internships and have limited time for this course.

So, here is my hypothesis:
- H0: There is no score difference between the 2020 intake and the 2021 intake.
- H1: The 2020 intake students perform differently from the 2021 intake students.
I first need to separate you into two groups according to your enrollment year. It is easy to do as the last four characters of your SMU Username represent your enrollment year, as you can see from the following summary.
str(df[, c("Username")])
## chr [1:42] "xiaoyu.ai.2020" "hqchen.2020" "jiayi.chen.2021" ...
What we need to do is to extract the last four characters from each Username and assign it to a new variable intake. There are many ways to do this and the easiest is to use the str_sub() from the package:stringr which is also part of the package:tidyverse package.
df <- df %>% mutate(intake = str_sub(Username, -4, -1),
intake2020 = ifelse(intake == "2020", 1, 0))
Another way is to use the sub() function and the regular expression^[Regular expression is important if you want to analyze textual data. Although we don’t cover in this course, I strongly recommend you teach yourself here.]. The following code is to replace anything before the . within your Username with nothing, thus the remaining will be the year of your enrollment^[There are some other ways to extract or replace substrings in a character vector, such as substr(); substring(); and others].
df <- df %>% mutate(intake = sub(".*\\.", "", Username),
intake2020 = ifelse(intake == "2020", 1, 0))
In the above code chunk I also create another variable intake2020 which takes the value of 1 if your enrollment year is 2020 and 0 if your enrollment year is 2021. This is a dummy variable which indicates your intake year^[This is a very important concept in data science called one-hot encoding which can help to code categorical variables.].
The following code is to summarize the mean scores for the two different and independent groups.
df %>%
group_by(intake) %>%
summarize(count = n(),
mean_score = mean(Score),
sd = sd(Score)) %>%
ungroup()
## # A tibble: 2 x 4
## intake count mean_score sd
## <chr> <int> <dbl> <dbl>
## 1 2020 11 5.82 1.47
## 2 2021 31 6.77 1.82
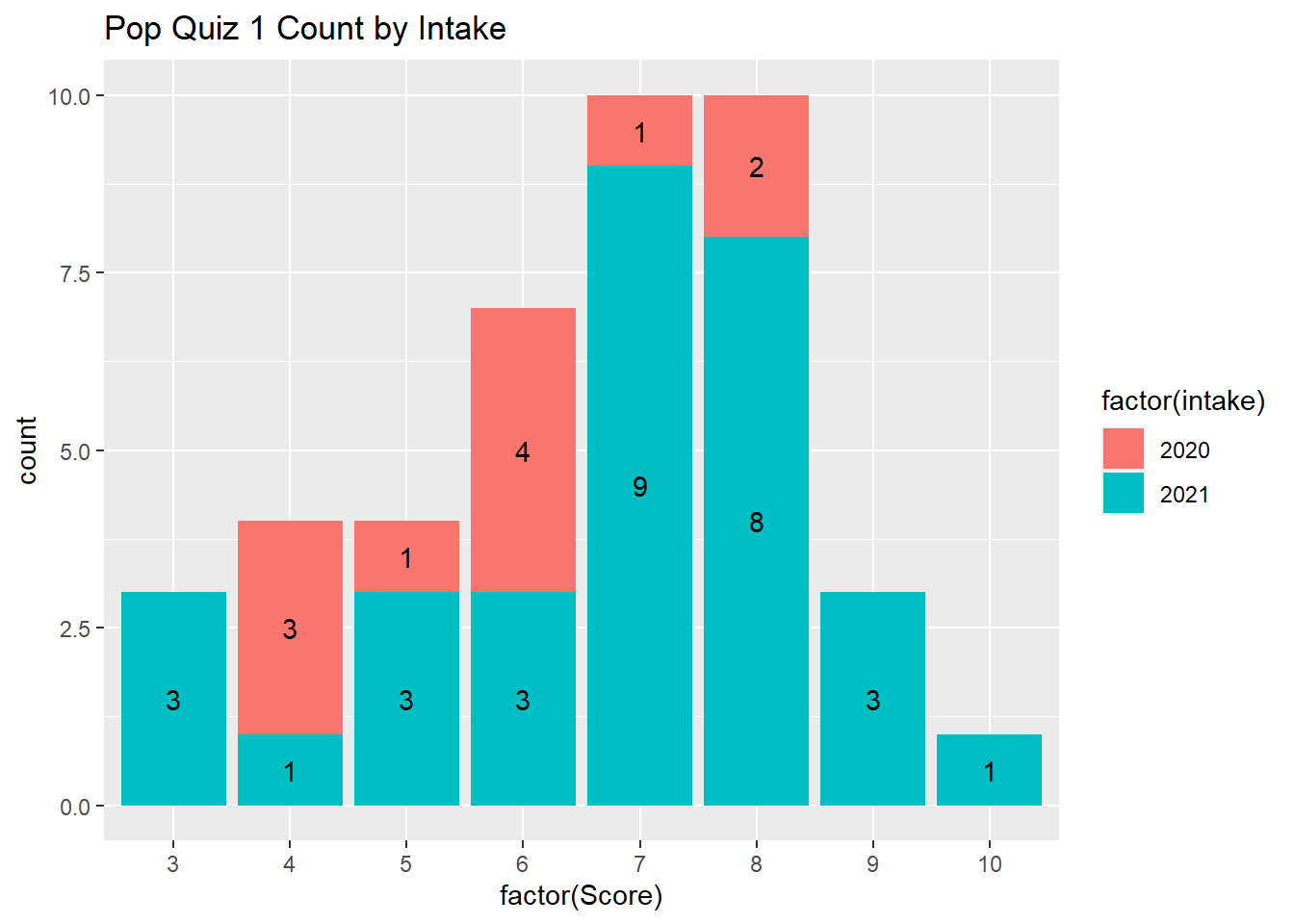
As you can see, there are 11 students from the 2020 intake and 31 students from the 2021 intake. It seems the intake 2020 students have a much lower average score than the 2021 intake students. But the standard deviation for the 2020 intake is lower than the standard deviation of the 2021 students.
I am presenting you two plots to furthur visualize the performance of the two different groups.
The following plot provides the frequency count by intake year.
df %>% ggplot(aes(x = factor(Score), fill = factor(intake)))+
geom_bar() +
geom_text(aes(label = ..count..),
stat = "count",
position = position_stack(vjust = 0.5)) +
ggtitle("Pop Quiz 1 Count by Intake")
The following plot presents the density by intake year.
df %>% ggplot(aes(x = Score, color = as.factor(intake))) +
geom_density(size = 1) +
ggtitle("Pop Quiz Density Plot") +
scale_color_economist(name = "data", labels = c("2020 Intake", "2021 Intake")) +
theme_economist()
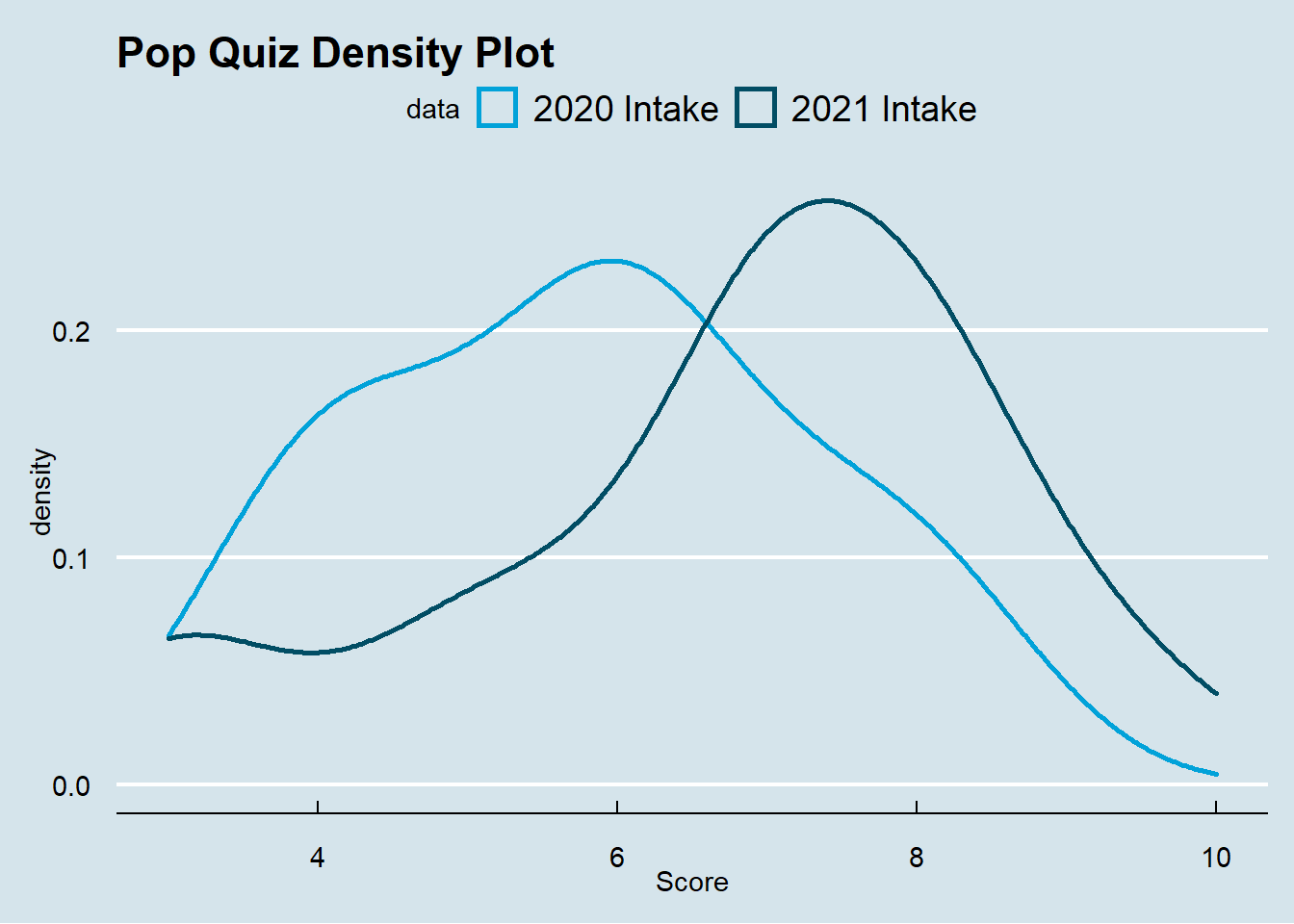
So, shall we reject our null hypothesis and conclude that the 2020 intake students perform worse than the 2021 intake students in the Pop Quiz 1? As a frequentist, we need to construct statistics to test whether these two groups perform differently.
Two Independent Samples T-Test
We first try the standard t-test for two independent samples. It is reasonable to assume the two groups are independent as we recruit students independently every year.
The t.test() function is from the Base R and the syntaxt is very simple^[This is a fundamental test which is applied very often in business. For example, in the A/B test I mentioned in our first class. It is basically a comparison of two independent groups.].
t.test(Score ~ intake2020, data = df)
##
## Welch Two Sample t-test
##
## data: Score by intake2020
## t = 1.7351, df = 21.688, p-value = 0.09692
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## -0.1876372 2.0996607
## sample estimates:
## mean in group 0 mean in group 1
## 6.774194 5.818182
As you can see, the t-statistic is 1.7351 and its corresponding p-value is 0.09692. As we are doing two-sided test and 0.05 is a confident significance level, we can conclude that we failed to reject the null hypothesis, ie, we failed to find any performance difference between 2020 intake and 2021 intake.
Regression Analysis
We may also perform regression analysis as follows.
model1 <- lm(Score ~ intake2020, df)
summary(model1)
##
## Call:
## lm(formula = Score ~ intake2020, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.7742 -0.8072 0.2258 1.2258 3.2258
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.7742 0.3125 21.681 <2e-16 ***
## intake2020 -0.9560 0.6105 -1.566 0.125
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.74 on 40 degrees of freedom
## Multiple R-squared: 0.05776, Adjusted R-squared: 0.0342
## F-statistic: 2.452 on 1 and 40 DF, p-value: 0.1253
The above regression result shows that the estimated coefficient on intake2020 is negative but insignificant. The t-value is -1.566 and its p-value is 0.125. As the p-value is larger than 0.05, we conclude that we failed to reject the null hypothesis, ie, we failed to find that the two groups of students perform differently.
In summary, I conclude that there is no significant difference in performance between the 2020 students and 2021 students.
A caveat of the above analysis is that we failed to control for other factors which may also affect your performance in the first quiz. Due to data availability, I am not able to go beyond this. So please interpret the results with caution.
Conclusion
This document shows the review of your performance in the first Pop Quiz in the Programming with Data course for the Master of Professional Accounting programme at Singapore Management University. You should be able to know your performance compared with your peers. You also have some understanding of the performance in two different intake students. In addition, we also review some fundamental data & analytics skills using R programming, including extract, transform and load (ETL) data, hypothesis testing, and data visualizations. I hope you will find this document useful.
You want to know more? Make an appointment with me at calendar.
Wang Jiwei
Associate Professor
My current research/teaching interests include digital transformation and data analytics in accounting.